

مدل پنهان مارکوف (به انگلیسی: Hidden Markov Model) یک مدل مارکوف آماری است که در آن سیستم مدل شده به صورت یک فرایند مارکوف با حالتهای مشاهده نشده (پنهان) فرض میشود. یک مدل پنهان مارکوف میتواند به عنوان سادهترین شبکه بیزی پویا در نظر گرفته شود.
در مدل عادی مارکوف، حالت بهطور مستقیم توسط ناظر قابل مشاهده است و بنابراین احتمالهای انتقال بین حالتها تنها پارامترهای موجود است. در یک مدل پنهان مارکوف، حالت بهطور مستقیم قابل مشاهده نیست، اما خروجی، بسته به حالت، قابل مشاهده است. هر حالت یک توزیع احتمال روی سمبلهای خروجی ممکن دارد؛ بنابراین دنبالهٔ سمبلهای تولید شده توسط یک مدل پنهان مارکوف اطلاعاتی دربارهٔ دنبالهٔ حالتها میدهد. توجه داشته باشید که صفت 'پنهان' به دنبالهٔ حالتهایی که مدل از آنها عبور میکند اشاره دارد، نه به پارامترهای مدل؛ حتی اگر پارامترهای مدل بهطور دقیق مشخص باشند، مدل همچنان 'پنهان' است.
مدلهای پنهان مارکوف بیشتر بهدلیل کاربردشان در بازشناخت الگو، مانند تشخیص صدا و دستخط، تشخیص اشاره و حرکت، برچسبگذاری اجزای سخن، بیوانفورماتیک و … شناختهشده هستند.
شرح ازنظر مسائل ظرفها
مدل پنهان مارکوف در حالت گسسته جز خانوادهٔ مسائل ظرفها قرار میگیرد. بهطور مثال از ربینر ۱۹۸۹: ظروف x1،x2،x3... و توپهای رنگی y1,y2,y3… را در نظر میگیریم، که نفر مقابل دنبالهای از توپها را مشاهده کرده ولی اطلاعی از دنبالهٔ ظرفهایی که توپها از آنها انتخابشده ندارد. ظرف n ام با احتمالی وابسته به ظرف n-1 ام انتخاب میشود و چون به انتخاب ظرفهای خیلی قبلتر وابسته نیست یک فرایند مارکوف است.
معماری مدل پنهان مارکوف
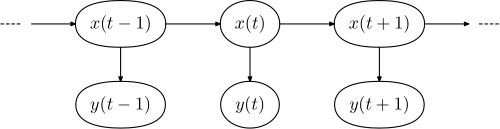
شکل زیر معماری کلی یک نمونه HMM را نشان میدهد. هر شکل بیضی یک متغیر تصادفی است که میتواند هر عددی از مقادیر را انتخاب کند. متغیر تصادفی یک حالت پنهان در زمان t و متغیر تصادفی مشاهده در زمان است. فلشها به معنای وابستگیهای شرطی میباشند. از شکل مشخص است که توزیع احتمال شرطی متغیر پنهان ، در همهٔ زمان هایt مقداری را برایx ارائه میدهد که فقط به مقدار متغیر پنهان وابسته است: مقادیر در زمانهای t-2 و قبلتر از آن هیچ اثری ندارند. این مشخصهٔ مارکف نامیده میشود. بهطور مشابه، مقدار متغیر مشاهدهای تنها به مقدار متغیر پنهان (هر دو در زمان خاص t) بستگی دارد. در حالت استاندارد مدل پنهان مارکوف که در اینجا در نظر گرفته شدهاست، فضای حالت متغیرهای پنهان گسسته است؛ درحالیکه متغیرهای مشاهدهای میتوانند گسسته یا پیوسته (از توزیع گوسین) باشند.




در مدل پنهان مارکوف دو نوع پارامتر وجود دارد:احتمال جابهجاییها (بین حالات) و احتمال خروجیها (یا مشاهدات). احتمال جابهجایی نحوهٔ انتقال از حالت t-1 به t را کنترل میکند.
فضای حالت پنهان شامل N مقدار ممکن برای حالات است. متغیر پنهان در زمان t میتواند هر یک از این مقادیر را اختیار کند. احتمال جابجایی احتمال این است که در زمان t در حالت k (یکی از حالات ممکن) و در زمان t+1 در حالت k1 باشیم. بنابرین در کل احتمال جابجایی وجود دارد. (مجموع احتمالات جابجایی از یک حالت به تمام حالتهای دیگر ۱ است)

احتمال خروجی، احتمال رخ دادن هر یک از اعضای مجموعهٔ مشاهدهای را برای هر حالت پنهان ممکنه مشخص میسازد که میتواند از یک توزیع احتمال پیروی کند. تعداد اعضای مجموعهٔ مشاهدهای بستگی به طبیعت متغیر مشاهدهای دارد.
اگر تعداد اعضای مجموعهٔ متغیرهای مشاهدهای برابر M باشد، بنابراین مجموع تعداد احتمالات خروجی NM میباشد/
مسایلی که به کمک مدل پنهان مارکوف حل میشود
با توجه به پارامترهای مدل پنهان مارکوف، میتوانیم مسایلی به صورت زیر را حل کنیم.
- Annotation: مدل را داریم به این معنی که احتمالات مربوط به انتقال از حالتی به حالت دیگر و همینطور احتمال تولید الفبا در هر حالت معلوم است. توالی از مشاهدات داده شده، میخواهیم محتملترین مسیری (توالی حالات) که توالی را تولید میکند را پیدا کنیم. الگوریتم viterbi میتواند اینگونه مسایل را به صورت پویا (Dynamic) حل کند.
- classification: مدل را داریم، توالی از مشاهدات داده شدهاست، میخواهیم احتمال (کل) تولید شدن این توالی توسط این مدل را (جمع احتمالات تمامی مسیرهایی که این توالی را تولید میکنند) حساب کنیم. الگوریتم forward
- Consensus: مدل را داریم، میخواهیم بدانیم محتملترین توالی که توسط این مدل تولید میشود (توالی که بیشترین احتمال را داراست) چیست. الگوریتم Backward
- Training: ساختار مدل را داریم به این معنی که تعداد حالات و الفبای تولیدی در هر حالت معلوم است، تعدادی توالی داریم (دادههای آموزش) میخواهیم احتمال انتقال بین حالات و همینطور احتمال تولید الفبا در هر حالت را محاسبه کنیم. الگوریتم Baum-Welch
یادگیری
وظیفه یادگیری در HMM، یافتن بهترین احتمالات جابجاییها و خروجیها بر اساس یک دنباله یا دنبالههایی از خروجی هاست. معمولاً این پارامترها به وسیله متد maximum likelihood بر اساس خروجی داده شده تخمین زده میشوند. هیچ الگوریتم قطعی برای حل این مسئله وجود ندارد ولی برای پیدا کردن maximum likelihood محلی میتوان از الگوریتمهای کارایی مانند Baum-welch algorithmو یا Baldi-chauvin algorithmاستفاده کرد. الگوریتم Baum-Welch نمونهای از الگوریتم forward-backwardو به صورت خاص موردی از الگوریتم expectation-maximization میباشد.
یک مثال ملموس
دو دوست به نامهای آلیس و باب را در نظر بگیرید. آنها دور از هم زندگی کرده و هر روز دربارهٔ کارهای روزمرهشان با هم تلفنی صحبت میکنند. فعالیتهای باب شامل "قدم زدن در پارک"،"خرید کردن" و "تمیز کردن آپارتمان" میشود. انتخاب اینکه هر روز کدام کار را انجام دهد منحصراً بستگی به هوای همان روز دارد. آلیس اطلاع دقیقی از هوای محل زندگی باب نداشته ولی از تمایلات کلی وی آگاه است (بنا به نوع هوا چه کاری را دوست دارد انجام دهد). بر اساس گفتههای باب در پایان هر روز، آلیس سعی میکند هوای آن روز را حدس بزند. آلیس هوا را یک زنجیرهٔ گسستهٔ مارکوف میپندارد که دو حالت "بارانی" و "آفتابی" دارد. اما بهطور مستقیم هوا را مشاهده نمیکند؛ بنابراین، حالات هوا بر او پنهان است. در هر روز احتمال اینکه باب به "قدم زدن"،"خرید کردن" و "تمیز کردن"بپردازد بستگی به هوا داشته و دارای یک احتمال مشخص است. مشاهدات مسئله شرح فعالیتهایی است که باب در انتهای هر روز به آلیس میگوید.
آلیس اطلاعات کلی دربارهٔ هوای محل زندگی باب و اینکه در هر نوع آب و هوا با چه احتمالی چه کار انجام میدهد را دارد. به عبارت دیگر پارامترهای مسئله HMM معلوم هستند که در کد زیر مشاهده میشوند:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy': {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny': {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy': {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny': {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}
در این کد start_probability نمایانگر احتمال رخ دادن هر یک از حالات HMM (بارانی یا آفتابی) در روز اولی که باب با آلیس صحبت میکند میباشد.transition_probability نمایانگر تغییر هوا بر اساس قواعد زنجیرهٔ مارکو است. بهطور مثال اگر امروز بارانی باشد به احتمال ۳۰٪فردا آفتابی است.emition_probability نمایانگر این است که باب علاقه دارد که در هر هوایی چه کار کند بهطور مثال در هوای بارانی با احتمال ۵۰٪ آپارتمانش را تمیز کرده یا در هوای آفتابی با احتمال ۶۰٪در پارک قدم میزند.

کاربردهای مدل پنهان مارکوف
تاریخچه
مدل پنهان مارکوف برای اولین بار در مجموعهمقالات آماری leonard E.Baum و سایر نویسندگان در نیمه دوم دهه ۱۹۶۰ توضیح داده شد. یکی از اولین کاربردهای HMM تشخیص گفتار بوده که در اواسط دههٔ ۱۹۷۰ شروع شد. HMM در نیمهٔ دوم ۱۹۸۰ وارد حوزهٔ آنالیز دنبالههای بیولوژیکی، بهطور خاص DNA شد. از آن پس، کاربرد آن در بیوانفورماتیک گسترش یافت.
انواع مدل پنهان مارکوف
مدل پنهان مارکوف میتواند فرایندهای پیچیده مارکوف را که حالتها بر اساس توزیع احتمالی مشاهدات را نتیجه میدهند، مدل کند. بهطور مثال اگر توزیع احتمال گوسین باشد در چنین مدل مارکوف پنهان خروجی حالتها نیز از توزیع گوسین تبعیت میکنند. علاوه بر این مدل پنهان مارکوف میتواند رفتارهای پیچیدهتر را نیز مدل کند. جایی که خروجی حالتها از ترکیب دو یا چند توزیع گوسین پیروی کند که در این حالت احتمال تولید یک مشاهده از حاصلضرب گوسین انتخاب شدهٔ اولی در احتمال تولید مشاهده از گوسین دیگر به دست میآید.
فرایند مارکوف گسسته
یک سیستم مانند شکل زیر را که در هر لحظه در یکی از حالت متمایز S1,... ,SN است در نظر بگیرید. در زمانهای گسسته و با فواصل منظم، حالت سیستم با توجه به مجموعهای از احتمالات تغییر میکند. برای زمانهای… ,t=۱٬۲ حالت در لحظه t را با qt نشان میدهیم. برای یک توصیف مناسب از سیستم فعلی نیاز به دانستن حالت فعلی در کنار تمام حالات قبلی میباشد. برای یک حالت خاص از زنجیره مارکوف مرتبه اول، توصیف احتمالاتی تنها با حالت فعلی و حالت قبلی مشخص میشود.



حال تنها فرایندهایی را در نظر میگیریم که در آنها سمت راست رابطه فوق مستقل از زمان است و به همین دلیل ما مجموعهای از احتمالات انتقال بین حالتها را خواهیم داشت.

که در آن احتمال انتقال بین حالات دارای خواص زیر است.


فرایند تصادفی فوق را مدل مارکوف قابل مشاهده میگویند زیرا خروجی مدل مجموعهای از حالات است که قرار گرفتن در آنها متناظر با یک مشاهده میباشد. ما میتوانیم دنباله مشاهدات مورد انتظار خود را تولید کنیم و احتمال وقوع آن در زنجیره مارکوف را محاسبه نماییم. برای مثال با داشتن دنباله مشاهدات احتمال وقوع آن به صورت زیر بیان میشود.



یکی دیگر از مواردی که مطرح میشود این است که اگر سیستم در حالت باشد با چه احتمالی به حالت میرود و با چه احتمالی در همان حالت باقی میماند.


مرتبه مدل مارکوف
۱- مدل مارکوف مرتبه صفر
یک مدل مارکوف از مرتبه صفر هیچ حافظهای ندارد و برای هر t و t' در دنباله سمبلها، خواهد بود. مدل مارکوف از مرتبه صفر مانند یک توزیع احتمال چند جملهای میباشد.

۲- مدل مارکوف مرتبه اول
یک مدل مارکوف مرتبه اول دارای حافظهای با طول ۱ میباشد. توزیع احتمال در این مدل به صورت زیر مشخص میشود.

تعریف فوق مانند این است که k مدل مارکوف در مرتبه صفر برای هر داشته باشیم.

۳- مدل مارکوف مرتبه m ام
مرتبه یک مدل مارکوف برابر است با طول حافظهای که مقادیر احتمال ممکن برای حالت بعدی به کمک آن محاسبه میشود. برای مثال، حالت بعدی در یک مدل مارکوف از درجه ۲ (مدل مارکوف مرتبه دوم) به دو حالت قبلی آن بستگی دارد.
مثال ۱: برای مثال اگر یک سکه معیوب A داشته باشیم که احتمالات شیر یا خط آمدن برای آن یکسان نباشد، میتوان آن را با یک مدل مارکوف درجه صفر با استفاده از احتمالات (pr(H و (pr(H توصیف نمود.
pr(H)=0.6, pr(T)=۰٫۴
مثال ۲: حال فرض کنید که سه سکه با شرایط فوق در اختیار داریم. سکهها را با اسامی B, A و C نامگذاری مینماییم. آنگاه برای توصیف روال زیر به یک مدل مارکوف مرتبه اول نیاز داریم:
- فرض کنید سکه X یکی از سکههای A یا B باشد.
- مراحل زیر را تکرار میکنیم.
a) سکه X را پرتاب میکنیم و نتیجه را مینویسیم.
b) سکه C را نیز پرتاب میکنیم.
c) اگر سکه C خط آمد، آنگاه سکه X را تغییر میدهیم (A را با B یا B را با A جایگزین میکنیم) و در غیر این صورت تغییری در سکهها نمیدهیم.
انجام روال فوق مدل مارکوف مرتبه اول زیر را نتیجه خواهد داد.

یک پردازش مارکوفی مانند نمونه فوق در طول پیمایش احتمالات، یک خروجی نیز خواهد داشت. یک خروجی نمونه برای پردازش فوق میتواند به شکل HTHHTHHttthtttHHTHHHHtthtthttht باشد.

مدل مارکوف فوق را میتوان به صورت نموداری از حالات و انتقالها نیز نشان داد. کاملاً مشخص است که اینگونه بازنمایی از مدل مارکوف مانند بازنمایی یک ماشین انتقال حالت محدود است که هر انتقال با یک احتمال همراه میباشد
مدل پنهان مارکوف (HMM)
تا اینجا ما مدل مارکوف، که در آن هر حالت متناظر با یک رویداد قابل مشاهده بود را معرفی نمودیم. در این بخش تعریف فوق را گسترش میدهیم، به این صورت که در آن، مشاهدات توابع احتمالاتی از حالتها هستند. در این صورت مدل حاصل یک مدل تصادفی با یک فرایند تصادفی زیرین است که پنهان است و تنها توسط مجموعهای از فرایندهای تصادفی که دنباله مشاهدات را تولید میکنند قابل مشاهده است.
برای مثال فرض کنید که شما در یک اتاق هستید و در اتاق مجاور آن فرد دیگری سکههایی را به هوا پرتاب میکند و بدون اینکه به شما بگوید این کار را چگونه انجام میدهد و تنها نتایج را به اطلاع شما میرساند. در این حالت شما با فرایند پنهان انداختن سکهها و با دنبالهای از مشاهدات شیر یا خط مواجه هستید. مسئلهای که اینجا مطرح میشود چگونگی ساختن مدل مارکوف به منظور بیان این فرایند تصادفی است. برای مثال اگر تنها مشاهدات حاصل از انداختن یک سکه باشد، میتوان با یک مدل دو حالته مسئله را بررسی نمود. یک مدل پنهان مارکوف را میتوان با تعیین پارامترهای زیر ایجاد نمود:
تعداد حالات ممکن: تعداد حالتها در موفقیت مدل نقش به سزایی دارد و در یک مدل پنهان مارکوف هر حالت با یک رویداد متناظر است. برای اتصال حالتها روشهای متفاوتی وجود دارد که در عمومیترین شکل تمام حالتها به یکدیگر متصل میشوند و از یکدیگر قابل دسترسی میباشند. تعداد مشاهدات در هر حالت: تعداد مشاهدات برابر است با تعداد خروجیهایی که سیستم مدل شده خواهد داشت.
N تعداد حالتهای مدل M تعداد سمبلهای مشاهده در الفبا، اگر مشاهدات گسسته باشند آنگاه M یک مقدار نا محدود خواهد داشت.

ماتریس انتقال حالت:یک مجموعه از احتمالات در بین حالتها
![{\displaystyle \ A=[a_{ij}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c2e5be58535cfa69a95badb38fd3533bfb6235e)

که در آن بیانگر حالت فعلی میباشد. احتمالات انتقال باید محدودیتها طبیعی یک توزیع احتمال تصادفی را برآورده نمایند. این محدودیتها شامل موارد زیر میگردند



برای حالات مدل ارگودیک برای تمامi وjها مقدار بزرگتر از صفر است و در موردی که اتصالی بین حالات وجود ندارد است.


توزیع احتمال مشاهدات: یک توزیع احتمال برای هر یک از حالتها


که در آن بیانگرkامین سمبل مشاهده شده در الفبا است و بیانگر بردار پارامترهای ورودی فعلی میباشد. در مورد مقادیر احتمال حالتها نیز شرایط موجود در نظریه احتمال باید رعایت گردند.




اگر مشاهدات به صورت پیوسته باشند، باید به جای احتمالهای گسسته از یک تابع چگالی احتمال پیوسته استفاده شود. معمولاً چگالی احتمال به کمک یک مجموع وزندار از M توزیع نرمال μ تخمین زده میشود.

که در آن ،>,,, به ترتیب ضریب بردار میانگین، ضریب وزندهی و ماتریس کواریانس میباشند. در رابطه فوق مقادیر باید شرایط زیر را ارضا نماید:






توزیع احتمال حالت آغازین
که در آن


به این ترتیب ما میتوانیم یک مدل پنهان مارکوف با توزیع احتمال گسسته را با استفاده از سهگانه زیر مشخص نماییم.

همچنین یک مدل پنهان مارکوف با توزیع احتمال پیوسته به صورت زیر نشان داده میشود.

انواع مدلهای پنهان مارکوف و HMM پیوسته
همانطور که گفته شد نوع خاصی از HMM وجود دارد که در آن تمام حالات موجود با یکدیگر متصل هستند. لیکن مدل مخفی مارکوف از لحاظ ساختار و اصطلاحاً توپولوژی انواع مختلف دارد. همانطور که گفته شد برای مدل ارگودیک برای تمام i و jها است و ساختار مدل مثل یک گفتار کامل است که راسها در آن دارای اتصالات بازگشتی نیز میباشند. لیکن برای کاربردهای متفاوت و با توجه به پیچیدگی فرایند نیاز به ساختار متفاوتی وجود دارد. از جمله این ساختارها که به شکل گستردهای در کاربردهای شناسایی گفتار مبتنی بر واج و شناسایی گوینده مورد استفاده قرار میگیرد، مدل چپ به راست یا مدل بکیس است. این مدل که ساختار آن را در شکل ۲ نیز میبینید، دارای اتصالات چپ به راست است و برای مدل کردن سیگنالهایی که خواص آنها با زمان تغییر میکند مورد استفاده قرار میگیرد. در مدل چپ به راست تنها یک حالت ورودی وجود دارد که همان حالت اول است و به این ترتیب:

مدلهای ارگودیک و چپ به راست مدلهای HMM پایه هستند و در پردازش گفتار نیز بیشترین کاربرد را دارا میباشند. هرچند میتوان با اتصال چندین مدل یا تغییر در ساختار اتصالات آن مدلهایی با انعطافپذیری بیشتری ایجاد نمود. شکل ۲-ج یک نمونه از مدل موازی چپ به راست، که شامل دو مدل چپ به راست است، را نشان میدهد.


در قسمتهای قبل مدلهای HMM برای مجموعه مشاهدات گسسته را مورد بررسی قرار دادیم. اگر چه میتوان با چندیسازی تمام فرایندهای پیوسته را به فرایندهای با دنباله مشاهدات گسسته تبدیل نمود، اما این کار ممکن است باعث افت مدل شود. در مدل HMM پیوسته احتمال قرار گرفتن مشاهدات در یک حالت را با توابع چگالی احتمال نشان میدهند. در این شرایط برای هر حالت i و ورودی O، احتمال مشاهده به صورت یک توزیع شامل M مخلوط نشان داده میشود:



مدل مخلوط گاوسی
مدل مخلوط گوسی یکی از مهمترین روشهای مدل کردن سیگنال است که در واقع شبیه یک HMM یک حالته است که تابع چگالی احتمال آن حالت دارای چندین مخلوط نرمال میباشد. احتمال تعلق بردار آزمایشیd به یک مدل مخلوط گاوسی دارای M مخلوط به شکل زیر بیان میشود:

که در آن وزن مخلوط و به ترتیب بردار میانگین و ماتریس کوواریانس توزیع نرمال هستند. ماتریس کوواریانس مدل GMM معمولاً به صورت قطری در نظر گرفته میشود، گرچه امکان استفاده از ماتریس کامل نیز وجود دارد.



برای بهدست آوردن پارامترهای مدل GMM، شامل وزن مخلوطهای گاوسی و میانگین و کواریانس توزیعها، از الگوریتم ماکزیمم نمودن امید ریاضی(EM)استفاده میشود. باید توجه داشت که تعداد مخلوطهای گاوسی با تعداد نمونههای موجود آموزشی رابطه مستقیم دارند و نمیتوان با مجموعه دادهای ناچیز یک مدل GMM دارای تعداد بیش از حد از مخلوطها را آموزش داد. در تشکیل و آموزش مدل GMM مانند تمام روشهای تشکیل مدل رعایت نسبت میزان پیچیدگی مدل و نمونههای آموزشی الزامی میباشد.
فرضیات تئوری مدل پنهان مارکوف
برای اینکه مدل پنهان مارکوف از لحاظ ریاضی و محاسباتی قابل بیان باشد فرضهای زیر در مورد آن در نظر گرفته میشود.
۱- فرض مارکوف
با داشتن یک مدل پنهان مارکوف، احتمال انتقال از حالت i به حالت j به صورت زیر تعریف میشود:

به بیان دیگر فرض میشود که حالت بعدی تنها به حالت فعلی بستگی دارد. مدل حاصل از فرض مارکوف یک مدل HMM مرتبه صفر میباشد. در حالت کلی، حالت بعدی میتواند با k حالت قبلی وابسته باشد. این مدل که مدل HMM مرتبه k ام گفته میشود، با استفاده از احتمالات انتقال به صورت زیر تعریف میگردد.

به نظر میرسد که یک مدل HMM از مرتبه بالاتر باعث افزایش پیچیدگی مدل میشود. علیرغم اینکه مدل HMM مرتبه اول متداولترین مدل است، برخی تلاشها برای استفاده از مدلهای دارای مرتبه بالاتر نیز در حال انجام میباشد.
۲- فرض ایستایی (stationarity)
در اینجا فرض میشود که احتمال انتقال در بین حالات از زمان واقعی رخداد انتقال مستقل است. در این صورت میتوان برا ی هر نوشت


۳- فرض استقلال خروجی
در این حالت فرض میشود که خروجی (مشاهدات) فعلی به صورت آماری از خروجی قبلی مستقل است. میتوان این فرض را با داشتن دنبالهای از خروجیها مانند بیان نمود:

آنگاه مطابق با این فرض برای مدل HMM با نام خواهیم داشت:


اگر چه بر خلاف دو فرض دیگر این فرض اعتبار کمتری دارد. در برخی حالات این فرضیه چندان معتبر نیست و موجب میشود که مدل HMM با ضعفهای عمدهای مواجه گردد.
مسئله ارزیابی و الگوریتم پیشرو (forward)
در این حالت مسئله این است که با داشتن مدل و دنباله مشاهدات باید مقدار را پیدا نماییم. میتوانیم این مقدار را با روشهای آماری مبتنی بر پارامترها محاسبه نماییم. البته این کار به محاسباتی با پیچیدگی احتیاج دارد. این تعداد محاسبات حتی برای مقادیر متوسط t نیز بسیار بزرگ است. به همین دلیل لازم است که راه دیگری برای این محاسبات پیدا نماییم. خوشبختانه روشی ارائه شدهاست که پیچیدگی محاسباتی کمی دارد و از متغیر کمکی با نام متغیر پیشرو استفاده میکند.>





متغیر پیشرو به صورت یک احتمال از دنباله مشاهدات تعریف میشود که در حالت i خاتمه مییابد. به بیان ریاضی:

آنگاه به سادگی مشاهده میشود که رابطه بازگشتی زیر برقرار است.


که در آن


با داشتن این رابطه بازگشتی میتوانیم مقدار زیر را محاسبه نماییم.

و آنگاه احتمال به صورت زیر محاسبه خواهد شد:

پیچیدگی محاسباتی روش فوق که به الگوریتم پیشرو معروف است برابر با است، که در مقایسه با حالت محاسبه مستقیم که قبلاً گفته شد، و دارای پیچیدگی نمایی بود، بسیار سریعتر است.

روشی مشابه روش فوق را میتوان با تعیین متغیر پسرو، ، به عنوان احتمال جزئی دنباله مشاهدات در حالت i تعریف نمود. متغیر پیشرو را میتوان به شکل زیر نمایش داد.



مانند روش پیشرو یک رابطه بازگشتی به شکل زیر برای محاسبه وجود دارد.


که در آن

میتوان ثابت کرد که

آنگاه میتوان با کمک هر دو روش پیشرو و پسرو مقدار احتمال را محاسبه نمود.
رابطه فوق بسیار مهم و مفید است و بخصوص برای استخراج روابط آموزش مبتنی بر گرادیان لازم میباشد.

مسئله کد گشایی و الگوریتم ویتربی (Viterbi Algorithm)
در این حالت میخواهیم با داشتن دنباله مشاهدات و مدل دنباله حالات بهینه برای تولید را بهدست آوریم.



یک راه حل این است که محتملترین حالت در لحظه t را بهدست آوریم و تمام حالات را به این شکل برای دنبالهٔ ورودی بهدست آوریم. اما برخی مواقع این روش به ما یک دنبالهٔ معتبر و بامعنا از حالات را نمیدهد. به همین دلیل، باید راهی پیدا کرد که یک چنین مشکلی نداشته باشد.
در یکی از این روشها که با نام الگوریتم Viterbi شناخته میشود، دنباله حالات کامل با بیشترین مقدار نسبت شباهت پیدا میشود. در این روش برای ساده کردن محاسبات متغیر کمکی زیر را تعریف مینماییم.

که در شرایطی که حالت فعلی برابر با i باشد، بیشترین مقدار احتمال برای دنباله حالات و دنباله مشاهدات در زمان t را میدهد. به همین ترتیب میتوان روابط بازگشتی زیر را نیز بهدستآورد.
![{\displaystyle \delta _{t+1}(j)=b_{j}(o_{t+1})[max\delta _{t}(i)a_{ij}],\qquad 1\leq i\leq N,\qquad 1\leq t\leq T-1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/341a45475d2d12accb08d82f405386c59e4075f8)
که در آن

به همین دلیل روال پیدا کردن دنباله حالات با بیشترین احتمال از محاسبهٔ مقدار و با کمک رابطهٔ فوق شروع میشود. در این روش در هر زمان یک اشاره گر به حالت برنده قبلی خواهیم داشت. در نهایت حالت را با داشتن شرط زیر بهدست میآوریم.



و با شروع از حالت ، دنباله حالات به شکل بازگشت به عقب و با دنبال کردن اشاره گر به حالات قبلی بهدست میآید. با استفاده از این روش میتوان مجموعه حالات مورد نظر را بهدستآورد. این الگوریتم را میتوان به صورت یک جستجو در گراف که نودهای آن برابر با حالتها مدل HMM در هر لحظه از زمان میباشند نیز تفسیر نمود
مسئله یادگیری
بهطور کلی مسئله یادگیری به این موضوع میپردازد که چگونه میتوان پارامترهای مدل HMM را تخمین زد تا مجموعه دادههای آموزشی به بهترین نحو به کمک مدل HMM برای یک کاربرد مشخص بازنمایی شوند. به همین دلیل میتوان نتیجه گرفت که میزان بهینه بودن مدل HMM برای کاربردهای مختلف، متفاوت است. به بیان دیگر میتوان از چندین معیار بهینهسازی متفاوت استفاده نمود، که از این بین یکی برای کاربرد مورد نظر مناسب تر است. دو معیار بهینهسازی مختلف برای آموزش مدل HMM وجود دارد که شامل معیار بیشترین شباهت (ML) و معیار ماکزیمم اطلاعات متقابل (Maximum Mutual Information (MMI)) میباشند. آموزش به کمک هر یک از این معیارها در ادامه توضیح داده شدهاست.
معیار بیشترین شباهت((Maximum Likelihood (ML)
در معیار ML ما سعی داریم که احتمال یک دنباله ورودی که به کلاس w تعلق دارد را با داشتن مدل HMM همان کلاس بهدست آوریم. این میزان احتمال برابر با نسبت شباهت کلی دنبالهٔ مشاهدات است و به صورت زیر محاسبه میشود.


با توجه به رابطه فوق در حالت کلی معیار ML به صورت زیر تعریف میشود.

اگر چه هیچ راه حل تحلیلی مناسبی برای مدل وجود ندارد که مقدار را ماکزیمم نماید، لیکن میتوانیم با استفاده از یک روال بازگشتی پارامترهای مدل را به شکلی انتخاب کنیم که مقدار ماکزیمم بهدست آید. روش Baum-Welch یا روش مبتنی بر گرادیان از جملهٔ این روشها هستند.


الگوریتم بام- ولش
این روش را میتوان به سادگی و با محاسبه احتمال رخداد پارامترها یا با محاسبه حداکثر رابطه زیر بر روی تعریف نمود.

![{\displaystyle \ Q(\lambda ,{\bar {\lambda }})=\sum _{q}p\{q|O,\lambda \}log[p\{O,q,{\bar {\lambda }}\}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a669bd0b99c6cb8b0638b6cea62136faf6886442)
یکی از ویژگیهای مخصوص این الگوریتم این است که همگرایی در آن تضمین شدهاست. برای توصیف این الگوریتم که به الگوریتم پیشرو- پسرو نیز معروف است، باید علاوه بر متغیرهای کمکی پیشرو و پسرو که قبلاً تعریف شدهاند، متغیرهای کمکی بیشتری تعریف شود. البته میتوان این متغیرها را در قالب متغیرهای پیشرو و پسرو نیز تعریف نمود.
اولین متغیر از این دست احتمال بودن در حالت i در زمان t و در حالت j در زمان t+1 است، که به صورت زیر تعریف میشود.

این تعریف با تعریف زیر معادل است.

میتوان این متغیر را با استفاده از متغیرهای پیشرو و پسرو به صورت زیر تعریف نمود.


متغیر دوم بیانگر احتمال پسین حالت i با داشتن دنباله مشاهدات و مدل پنهان مارکوف میباشد و به صورت زیر بیان میشود.

این متغیر را نیز میتوان در قالب متغیرهای پیشرو و پسرو تعریف نمود.
![{\displaystyle \gamma _{t}(i)=\left[{\frac {\alpha _{t}(i)\beta _{t}(i)}{\sum _{i=1}^{N}\alpha _{t}(i)\beta _{t}(i)}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/208320604d962f63ab6c3b1f4c30f35fafd0371c)
رابطه بین دو متغیر فوق به صورت زیر بیان میشود.

اکنون میتوان الگوریتم آموزش بام – ولش را با ماکزیمم کردن مقدار بهدستآورد. اگر مدل اولیهٔ ما باشد، میتوانیم متغیرهای پسرو و پیشرو و متغیرهای و را تعریف نمود. مرحلهٔ بعدی این است که پارامترهای مدل را با توجه به روابط بازتخمین زیر بهروزرسانی کنیم.





فرمولهای بازتخمین را میتوان بهراحتی به شکلی تغییر داد که با توابع چگالی پیوسته نیز قابل استفاده باشند.
الگوریتم حداکثرسازی امید ریاضی (Expectation Maximization)
الگوریتم حداکثرسازی امید ریاضی یا EM به عنوان یک نمونه از الگوریتم بام – ولش در آموزش مدلهای HMM مورد استفاده قرار میگیرد. الگوریتم EM دارای دو فاز تحت عنوان Expectation و Maximization است. مراحل آموزش مدل در الگوریتم EM به صورت زیر است.
- مرحله مقدار دهی اولیه: پارامترهای اولیه مدل را تعیین مینماییم.
- مرحله امید ریاضی(Expectation): برای مدل موارد زیر را محاسبه میکنیم.

- مقادیر با استفاده از الگوریتم پیشرو
- مقادیر و با استفاده از الگوریتم پسرو


- مرحله ماکزیممسازی (Maximization): مدل را با استفاده از الگوریتم باز تخمین محاسبه مینماییم.
- مرحله بروزرسانی
- بازگشت به مرحله امید ریاضی

روال فوق تا زمانی که میزان نسبت شباهت نسبت به مرحله قبل بهبود مناسبی داشته باشد ادامه مییابد.
روش مبتنی بر گرادیان
در روش مبتنی بر گرادیان هر پارامتر از مدل با توجه به رابطه زیر تغییر داده میشود.

![{\displaystyle \ \Theta ^{new}=\Theta ^{old}-\eta \left[{\frac {\partial j}{\partial \Theta }}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0b0046e064301e13c53db6ae1b74307db96cadd2)
که در آن مقدار J با ید مینیمم شود. در این حالت خواهیم داشت.

از آنجا که مینیمم کردن J معادل است با مینیمم کردننیاز است است تا معیار ML بهینه بهدست آید. آنگاه مسئله، یافتن مقدار مشتق برای تمام پارامترهایاز مدل است. این کار را میتوان به سادگی با استفاده از مقدار


با مشتق گرفتن از رابطهٔ قبل به این نتیجه دست مییابیم:

از آنجا که در رابطهٔ فوق مقدار بر حسب بهدست میآید، میتوان رابطه بهدستآورد.

در روش مبتنی بر گرادیان، مقدار را باید برای پارامترهای (احتمال انتقال) و (احتمال مشاهدات) بهدستآورد.


استفاده از مدل HMM در شناسایی گفتار
بحث شناسایی اتوماتیک گفتار را میتوان از دو جنبه مورد بررسی قرار داد.
- از جنبه تولید گفتار
- از جنبه فهم و دریافت گفتار
مدل پنهان مارکوف (HMM) تلاشی است برای مدلسازی آماری دستگاه تولید گفتار و به همین دلیل به اولین دسته از روشهای شناسایی گفتار تعلق دارد. در طول چندین سال گذشته این روش به عنوان موفقترین روش در شناسایی گفتار مورد استفاده قرار گرفتهاست. دلیل اصلی این مسئله این است که مدل HMM قادر است به شکل بسیار خوبی خصوصیات سیگنال گفتار را در یک قالب ریاضی قابل فهم تعریف نماید.
در یک سیستم ASR مبتنی بر HMM قبل از آموزش HMM یک مرحله استخراج ویژگیها انجام میگردد. به این ترتیب ورودی HMM یک دنباله گسسته از پارامترهای برداری است. بردارهای ویژگی میتواند به یکی از دو طریق بردارهای چندیسازی شده یا مقادیر پیوسته به مدل HMM آموزش داده شوند. میتوان مدل HMM را به گونهای طراحی نمود که هر یک از این انواع ورودیها را دریافت نماید. مسئله مهم این است که مدل HMM چگونه با طبیعت تصادفی مقادیر بردار ویژگی سازگاری پیدا خواهد کرد.
استفاده از HMM در شناسایی کلمات جداگانه
در حالت کلی شناسایی واحدهای گفتاری جدا از هم به کاربردی اطلاق میشود که در آن یک کلمه، یک زیر کلمه یا دنبالهای از کلمات به صورت جداگانه و به تنهایی شناسایی شود. باید توجه داشت که این تعریف با مسئله شناسایی گفتار گسسته که در آن گفتار به صورت گسسته بیان میشود متفاوت است. در این بین شناسایی کلمات جداگانه کاربرد بیشتری به نسبت دو مورد دیگر دارد و دو مورد دیگر بیشتر در عرصه مطالعات تئوری مورد بررسی قرار میگیرند. برای این کاربرد راه حلهای مختلفی وجود دارد زیرا معیارهای بهینهسازی متفاوتی را برای این منظور معرفی شدهاست و الگوریتمهای پیادهسازی شده مختلفی نیز برای هر معیار موجود است. این مسئله را از دو جنبه آموزش و شناسایی مورد بررسی قرار میدهیم.
آموزش
فرض میکنیم که فاز پیش پردازش سیستم دنباله مشاهدات زیر را تولید نماید:

پارامترهای اولیه تمام مدلهای HMM را با یک مجموعه از مقادیر مشخص مقدار دهی مینماییم.

در آغاز این مسئله را برای حالت clamped در نظر بگیرید. از آنجایی که ما برای هر کلاس از واحدها یک HMM داریم، میتوانیم مدلاز کلاس l را که دنباله مشاهدات فعلی به آن مربوط میشود، را انتخاب نماییم.


برای حالت free نیز به مانند حالت قبل میتوان مقدار نسبت شباهت را بهدستآورد.
![{\displaystyle \ L_{tot}^{free}=\sum _{m=1}^{N}L_{m}^{I}=\sum _{m=1}^{N}[\sum _{i\in \lambda _{m}}\alpha _{t}(i)\mathrm {B} _{t}(i)]\sum _{m=1}^{N}\sum _{i\in \lambda _{i}}\alpha _{T}(i)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/48e2d5288de6f92113a9fd886bb4cb6d940ecb4e)
که در آن بیانگر میزان شباهت دنبالهٔ مشاهدات فعلی به کلاس l در مدل است.


شناسایی
در مقایسه با آموزش، روال شناسایی بسیار سادهتر است. الگوریتم دنبالهٔ مشاهدات موردنظر را دریافت میکند.


در این حالت نرخ شناسایی به صورت نسبت بین واحدهای شناسایی صحیح به کل واحدهای آموزشی حساب میشود.
مشارکتکنندگان ویکیپدیا. «Hidden Markov model». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۲۷ ژوئن ۲۰۱۱.